

こんばんは、蓬莱です!
研究室のゼミで「Rを高速化するためにはsnowパッケージが使えるよ!」という発表がありました。研究でもブログでもRを使っている身として、非常にタメになった講義でした。
試しにネット上にある高速化の記事を検索すると、確かにsnowやffなどのパッケージを使った手法が多く見られました。R言語において、パッケージを使っての高速化は主流なのでしょう。
しかしながら、高速化の手法は何もそれだけではありません。コードを最適化することで、高速化を実現する例もあるのです。この記事では、パッケージを使わない高速化のやり方について伝授します!
パッケージを使いなさいという風潮
Rを速くしたいのなら、さっさと高速化パッケージのsnowやffを導入しなさい。
この助言は、多くのサイトや書籍で紹介されています。パッケージと聞くと少し面倒な印象もありますが、実際に使ってみたところ非常に簡単な処理で高速化に成功しました。
少しパッケージの勉強をして、高速化させたいプログラムに5行程度プログラムを追加すれば、高速化が望めるのです。これだけ簡単であれば、R技術者がこぞってパッケージを使いなさいというのも無理はありません。
snowやffパッケージの凄さを、以下の例でイメージしてみましょう。

未最適化+パッケージなしの状況
椅子を10個作る問題と言うのを考えます。図を見て分かる通り、この状態で作業を続ければ、全て作るのに丸10日間費やすことになります。
ここでは、まだ高速化を施していない状況とお考え下さい。
ここにパッケージを導入すると……。
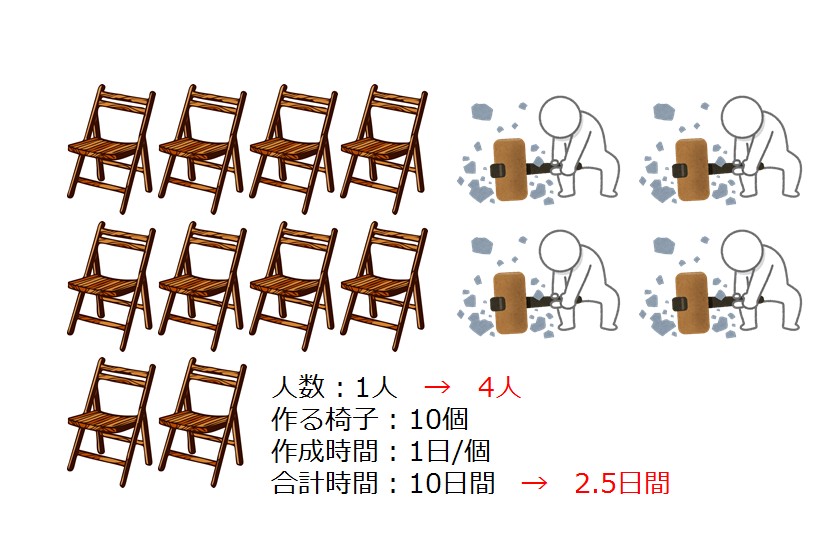
パッケージを使うと4人作業に!
単純に作業人数が増えるわけです。当たり前ですが、これならば実質4倍のスピードで椅子10個を達成することができますね!
たった数行追加するだけで、作業人数を増やせるパッケージは魅力的ですよね。この例題では人が増えるとしていますが、実際のパソコン内部では使用するコア数が増えるということになります。
コードを最適化するイメージ

作業者が効率の良い作り方を思いついたようです。
パッケージは作業人数を増やすことに相当しますが、コードを最適化するとはどのようなイメージでしょう?
答えは上記の画像にあります。ズバリ、作業時間を短くして効率化しているのです。
椅子1個に24時間かけていたのに対し、3時間で作り上げる方法を思いついたわけですから、8倍の高速化を実現したことになります。
Rを高速化する(初心者向け)
お待たせしました。
Rを使う人ならば必ずやっているであろう作業を題材にして、効率化する方法をお伝えします。
見る人が見れば「何だ、こんな初歩的なことか」と落胆するかもしれませんが、これは初心者編の記事なのでどうかご了承いただければと思います。
先ほどの例では、24時間→3時間で8倍の高速化を実現した例を挙げましたね。本当にコードの最適化だけで8倍も速くなるのかと疑われるかもしれませんが、どうぞご安心くださいませ。
私の実務上、1000倍は速くなったケースがあります。
system.time( a <- 1 ) #直接計測するやり方.1
fun1 <- function() { #関数を作って計測するやり方.2
a <- 1
}
system.time( fun1() )Rには、プログラムにかかる時間を計測してくれるsystem.time()という関数があります。上記の例のように、aに1を入れるだけの簡単なコードを2通りの方法で計測できます。
どちらも結果は同じになりますが、後者の方がプログラムが見やすいという都合の元、2番目のやり方で記事を進めていきます。
なお、タイムを計るPCのスペックは以下の通りです。今回はパッケージを使わないので、コア数はタイムに関係ありませんね。
- DELL Precision T1500
- Inter(R) Core(TM) i7 CPU 870 @ 2.93GHz
- メモリ16GB , CPUコア数4
必要な分だけ大きい箱を作ろう!
num <- 100000
fun1 <- function() {
Data.all <- c()
for(i in 1:num) Data.all <- c(Data.all , i)
}
fun2 <- function() {
Data.all <- rep(NA , num)
for(i in 1:num) Data.all[i] <- i
}
system.time( all1 <- fun1() )
system.time( all2 <- fun2() )
fun1():12.50秒 fun2() : 0.02秒
問題:1~100000まで入ったベクトルを”forループ”で作りなさい。
c <- 1:100000で済むじゃないかと思われるかもしれませんが、あえてforループで作ってみるという問題です。この問題に高速化のエッセンスが詰まっています。
fun1()の方では、最初に空のベクトルを作って、そこに数字を10万回入れています。
対してfun2()では、最初に必要な大きさのベクトルを作って、そこに数字を更新していくという操作になります。
たったこれだけで、600倍もの差が出ていますね。これはベクトルのサイズに注目すると、納得のいく理由が説明できます。
fun1()ではループに入る前のData.allは、サイズ(長さ)0の状態です。空のベクトルですから、length()をとっても0になりますよね。そしてループ1回目が終わるとサイズは1に、ループ2回目が終わればサイズは2になります。つまり、ループしていくたびにサイズが変わっているのです。
これに対し、fun2()はあらかじめ必要な長さを定義しています。最初のData.allで、すでにサイズ(長さ)100000の状態ですね。forループをしても、Data.allの要素を更新していくだけですから、サイズは一回たりとも変わりません。
こんな些細なサイズ変更に、意外と時間がかかってしまうようです。
もしも、何かしらの計算をしてベクトルにまとめていくという作業があれば、ぜひとも大きなベクトルを用意して、そこに更新するようにしてみてください。
fun1()のような空のベクトルに入れる作業を、fun2()のように大きなベクトルに更新していく形にすれば、数百倍・数千倍の速さを実現できると思いますよ!
なお、このサイズを変更しないという考えは、ベクトルのみにとどまりません。rbind() , cbind()についても同様のことが言えます。
これらも結局は、2つのデータフレームを連結する関数です。非常に便利ですが、サイズを変えていることには変わりありません。
よって、何百回もrbind()する作業があれば、そこは改善する必要があるでしょう。
forよりもapply()!
num <- 200000
Data <- data.frame("X"=1:num , "Y"=1:num , "Z"=1:num)
fun1 <- function() {
Data.all <- rep(NA , num)
for(i in 1:num) Data.all[i] <- sum(Data[i,])
return(Data.all)
}
fun2 <- function() apply(Data , 1 , sum)
system.time( res1 <- fun1() )
system.time( res2 <- fun2() )
fun1():59.49秒 fun2() : 0.45秒
高速化を目指す人が必ず目にする文章があります。それは「Rのforは遅すぎるから、できるだけapply()を使おう」という文章です。
上記のfun1()は単純にforで計算したもの、fun2()はapply()で計算したものになります。何か知らないけど、確かにapply()の方が速い事が分かりました。
しかし、なぜこんなことが起きるのでしょう? 浅学の身であるため詳しいことは書けませんが、世間が言うapply()の方が速いということは、このプログラムでよくわかります。
いっそループ処理をやめる全体ベクトル操作
num <- 200000
Data <- data.frame("X"=1:num , "Y"=1:num , "Z"=1:num)
fun2 <- function() apply(Data , 1 , sum)
fun3 <- function() {
ans <- Data$X + Data$Y + Data$Z
return(ans)
}
system.time( res2 <- fun2() )
system.time( res3 <- res3() )
fun2():0.45秒 fun2() : 0.00秒
確かにapply()の方が断然速かったですね。これは実際の結果を見て、強く驚きました。
しかし、だからと言って何も考えずapply()を多用していてはまだまだです。ここからはベクトル全体で計算するという、より一歩上の高速化を学んでおきましょう。
先ほどのapply()を使ったfun2()と、新しくfun3()を載せました。どちらも同じ処理結果になりますが、時間を見るとどうでしょう?
fun2()も相変わらず高速ですが、fun3()は0.00秒という驚異的な処理能力を見せました。これがベクトル全体で計算した効果です。
fun3()をよく見てみると、forやapply()などのループ関数がありません。このコードには、「この計算なら別にループして行ごとに計算する必要がないんじゃない?」というメッセージが含まれています。
Rでは、x <- c(1,2) と y <- c(3,4) があるとして、x+yとすれば 4,6と計算してくれます。これはベクトル全体を参照して、計算してくれるという機能になります。これを応用して、列を指定して足し算すれば、ループなしでも計算できるという理屈になるわけですね。
apply()は確かに高速ですが、その作業は順次行ごとに計算しているに過ぎません。それに対し、いわばすべての要素をほぼ同時に計算してくれるベクトル操作が、fun3()の内容になるのです。
ちなみにベクトル全体で行う操作は、例えnum <- 10000000と入れてみても一瞬で終わります。
fun1() : 2日 fun2():37.05秒 fun3() : 0.07秒
ループ処理における無駄な操作
num <- 10000000
fun1 <- function() {
for(i in 1:num) {
hosei1 <- 0.1 ; hosei2 <- 0.2
x <- i * hosei1 + hosei2
}
}
fun2 <- function() {
hosei <- 0.1 ; hosei2 <- 0.2
for(i in 1:num) {
x <- i * hosei + hosei2
}
}
system.time( fun1() )
system.time( fun2() )
fun2():1.89秒 fun2() : 1.14秒
他の人のプログラムを見ると、ループの中身に無駄があってビックリすることがあります。次はループ処理の中身を見直すことで、高速化につながる例を紹介しましょう。
fun1()とfun2()では、hosei1とhosei2をどこで定義しているかに違いがあります。
fun1()の場合はhosei1とhosei2の定義をループの中で行っているのに対し、fun2()の場合はループの外で定義しています。これだけの違いで、実行時間に差が出てくるのです。
この差の原因は非常に分かりやすく、hosei1とhosei2の定義回数が違うからです。fun1()ではforループの中に入れ込んでいるため、hosei1とhosei2を10000000回も定義し直しています。fun2()ではループの外で定義しているため、1回しか定義していませんね。
この例では無駄な定義が2つあったことになりますが、この法則を知らない人はもっと多く関係ない処理を入れている可能性があります。
forループの中にいらない計算(例えば、x+yなど)が入っていれば、なおさら遅くなります。上級者の方も、初心に戻ってforループの中身を見直してみましょう。
num <- 10000
fun1 <- function() {
for(i in 1:num) {
for(j in 1:num) {
x <- i ; y <- j
}
}
}
fun2 <- function() {
for(i in 1:num) {
x <- i
for(j in 1:num) {
y <- j
}
}
}
system.time(fun1())
system.time(fun2())
fun2():12.10秒 fun2() : 8.17秒
もう1つ同じような例を挙げます。先ほどの話を聞いた皆様なら、すぐに分かることでしょう。
fun1()では、xの定義を余分に行っています。fun2()が正しい書き方ですね。
コードの見た目としてはfun1()の方が軍配が上がりますが、高速化の面ではfun2()に大きく軍配が上がります。
forループに必要のないオブジェクト、計算などをループの外に置く。これだけの改善だけで高速化が望めるのであれば、たとえコードが汚く見えても実践していくべきだと思いますね!
最後に
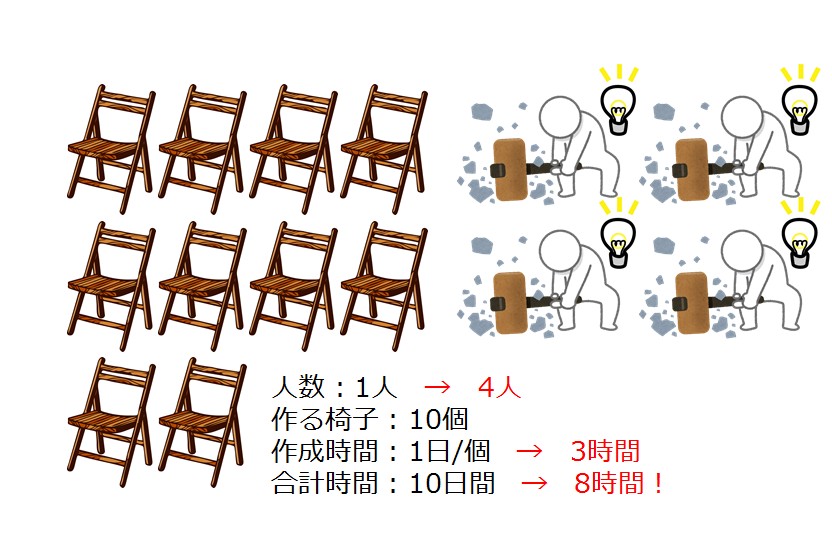
最適化とパッケージを使えば、効果はさらに倍増!
この記事では、初歩的な高速化の方法を提供しました。
この記事にある高速化の手法はすべて初歩的なものではありますが、R技術者にとって意外と抜けている知識です。
今回提示した情報を見て、目からウロコだった人は、ぜひ自身のプログラムを改善してみてください。きっと、相当なスピードになると思いますよ!
今回紹介した方法にパッケージを合わせれば、より効果的な高速化が望めます。上記の画像の例を使えば、椅子を効率的に作る方法を考え出したうえで、作業人数も増やしているという状態です。
蓬莱さんはまだまだ浅学なれど、もっと多くの効率化の方法を知りたいという方のために、最適化上級編の記事もご用意できます。この記事の需要が大きければ、追記して書くことにしましょうかね。