

こんばんは、蓬莱です!
今日はR言語のリストという機能について検討します。つい最近Rで「子作りセックスが頻繁に行われている時期」を分析していたとは思えないくらい、真面目な記事ですね。
リストの優れている部分は、データの形(ベクトル、行列、データフレーム)などを気にせず、どんなものでもリストに入れられるという点です。これは多くのサイトや書籍で述べられていることであります。
しかし、その特徴を述べているだけで、実際にどうやって使っていくかについて述べている情報は、ネットを含め皆無な気がします。
これではいけない。リストを実用的に使う例を示すため、蓬莱さんが一肌脱ぎますよ!
この記事の対象者
- リストの操作を一通り勉強したけど、どうやって実務に使っていけばいいか分からない人。
- データフレームではできない、リストならではの実用的な使い方を見てみたい人。
- リスト? データフレームさえあればそんなのいらないよって思う人。
この記事では上記のようなお悩みを持っている人たちに、何かしらのヒントになるような例を提示したいと思っています。
実はこの記事を書くまで、リストについて何も知りませんでした。修士の研究ではデータフレームを多用しており、リストを使うなんて露ほども考えていませんでした。
言うなればリスト初心者の記事ですが、頑張って色々調べましたのでご参考になれば幸いです。
1次元ベクトルをまとめたリスト

まずは手始めに、一次元のベクトルをたくさん格納した例を見ていきましょうか。
問題設定はこんな感じです。
「農作物について、都道府県ごとに収穫量をまとめたデータがあります。それらの農作物は都道府県によっては収穫できなかったところがあり、収穫できた県だけ収穫量を教えてくれました。日本全国でどれだけ農作物が収穫できたか知りたいです」
apple <- c(11 , 14 , 14 , 22 , 16 , 18)
grape <- c(3 , 6 , 3)
orange <- c(41 , 46 , 32 , 52)
banana <- c(53 , 52 , 68 , 62 , 55)
itigo <- c(11 , 9)
rice <- c(18 , 19 , 22 , 22 , 19 , 18)
komugi <- c(8 , 10 , 7)
sobako <- c(1 , 2)
こちらが扱うデータになります。
農作物別に、ベクトルでまとめておきました。りんごであれば、6県でしか取れなかったというデータになりますね。
見ての通り、ベクトルの長さがそれぞれ違います。こんな状態でも、リストには格納することができます。
list <- list(apple , grape , orange , banana , itigo ,
rice , komugi , sobako)
list
[[1]]
[1] 11 14 14 22 16 18
[[2]]
[1] 3 6 3
[[3]]
[1] 41 46 32 52
[[4]]
[1] 53 52 68 62 55
[[5]]
[1] 11 9
[[6]]
[1] 18 19 22 22 19 18
[[7]]
[1] 8 10 7
[[8]]
[1] 1 28つのベクトルをリスト化しました!
これがlistの醍醐味ですよね。データの型(ベクトルや行列など)のみならず、長さが違うベクトルも同じリストの中に収納することができます。
データフレームでは、同じようにまとめることはできませんよね。同じ個数のものしかデータフレームにまとめることができないため、みんな大好き「length differ」のエラーが出てしまいます。
もしもリストを知らなかった場合、たくさんのベクトルを定義していかなければなりません。今回は8つの作物ということで少ないベクトルで済みましたが、実問題だと相当な数のベクトルを作らなければいけないこともあるはずです。
1000個ものベクトルを扱うのと、1000個の要素が詰まったリスト1つを扱うのと、どちらがやりやすいかは明白です。
小さなベクトルをたくさん使うよりも、リスト1つで情報をまとめられるのはものすごい便利ですよね。
res <- lapply(list , sum)
res
[[1]]
[1] 95
[[2]]
[1] 12
[[3]]
[1] 171
[[4]]
[1] 290
[[5]]
[1] 20
[[6]]
[1] 118
[[7]]
[1] 25
[[8]]
[1] 3計算においても超便利!
lapply()を使えば、なんと一行で全ての要素を計算できます!
問題設定の通り、日本全国で収穫した農作物の量をsum()で合計してみました。結果から、きちんと全要素について同じ処理を行っていることが分かりますね。
例題において、たとえリストの要素が1000だとしても、lapply()一つで全てを計算してくれます。forループを1000回やる必要はないわけですね(苦笑)
res <- sapply(list , sum)
res
[1] 95 12 171 290 20 118 25 3
「結果は各要素1つずつしか出てこないし、リストで返ってくるのはウザい」。
そう思った方には、sapply()がおすすめです!
sapply()を使うと結果がベクトルで返ってくるので、その後の結果の利用もやりやすくなりますよ!
(結果がどうしてもベクトルにできない場合、データの型は行列になります)
1階層リストの実用例

リストは階層にしてこそ、真価を発揮する。リスト初心者の蓬莱さんは、そんな妄想を抱いております。
次は階層構造を作って、実務に役立てられないか考えましょう。
問題設定はこちらです。
「学年ごとに1つしかクラスがない学校があります。少子化がすごいので、1学年3人しか生徒がいません。 この状況をクラス別にリスト化し、各学生の成績をまとめたい。csvには合計点がないので、リスト化した後にこれを計算したい」
grade1 <- read.table("grade1.csv" , header=T , sep=",")
grade2 <- read.table("grade2.csv" , header=T , sep=",")
grade3 <- read.table("grade3.csv" , header=T , sep=",")
grade4 <- read.table("grade4.csv" , header=T , sep=",")
grade5 <- read.table("grade5.csv" , header=T , sep=",")
grade6 <- read.table("grade6.csv" , header=T , sep=",")
list <- list()
list <- c(list , c1=list(grade1) , c2=list(grade2) , c3=list(grade3)
, c4=list(grade4) , c5=list(grade5) , c6=list(grade6))ずいぶんと適当な問題設定ですね。
まずはデータを読み込んで、リスト化してみましょう。
> list
$c1
meibo jp math eng soc sci
1 1 56 55 63 65 60
2 2 74 67 78 80 73
3 3 88 87 90 92 87
$c2
meibo jp math eng soc sci
1 1 70 61 72 72 70
2 2 72 68 77 77 73
3 3 81 75 88 93 86
$c3
meibo jp math eng soc sci
1 1 69 61 70 73 68
2 2 56 47 63 66 61
3 3 88 87 88 93 85
$c4
meibo jp math eng soc sci
1 1 71 68 72 75 67
2 2 68 62 73 77 70
3 3 74 65 82 83 82
$c5
meibo jp math eng soc sci
1 1 75 66 82 83 80
2 2 74 71 78 79 77
3 3 64 62 73 78 70
$c6
meibo jp math eng soc sci
1 1 88 87 88 93 85
2 2 77 74 80 81 78
3 3 69 67 71 72 70
4 4 79 74 80 84 77学年別にまとめたリスト!
大したものはできないだろうと見くびっていましたが、これはなかなか凄いですね。学年ごとにブロック分けされていて、生徒の成績が一望できます。
これはデータフレームより分かりやすいですね。
fun1 <- function(x){ x$sum <- apply(x[,2:6] , 1 , sum) ; return(x) } #短縮形
result <- lapply(list , fun1)
result
$c1
meibo jp math eng soc sci sum
1 1 56 55 63 65 60 299
2 2 74 67 78 80 73 372
3 3 88 87 90 92 87 444
$c2
meibo jp math eng soc sci sum
1 1 70 61 72 72 70 345
2 2 72 68 77 77 73 367
3 3 81 75 88 93 86 423
$c3
meibo jp math eng soc sci sum
1 1 69 61 70 73 68 341
2 2 56 47 63 66 61 293
3 3 88 87 88 93 85 441
#・・・省略綺麗なリストができたところで、各学生の合計点を出したいと思います。
今回は階層構造と言うことで、fun1というapply()を含む関数を作りました。lapply()だけだと「行ごとに足すという動作ができない」ため、このような処理をしています。
ちなみに農作物の例題の様に、単純にlappy(list , sum)としてしまうと、学年ごとに全ての数字を足してしまうことになります。
何を言っているか分からないと思うので、これは後日lapply()の記事を作成することにします。
lapply()とapply()を組み合わせて使う手法は、リストを使いこなすのに必要な知識だと思うので、期待していてくださいね。
2017/10/20 追記:おまたせしました!
参考記事:階層リストはこう操作する!R言語のlapply,sapplyのイメージを学ぼう
fun1 <- function(x) { #短縮していない形。下のfun1と同じ機能
tori <- apply(x[,2:6] , 1 , sum)
x$sum <- tori
return(x)
}
fun1 <- function(x){ x$sum <- apply(x[,2:6] , 1 , sum) ; return(x) } #短縮形
fun1については少し短縮しすぎたので、分解した分かりやすい形も載せておきますね。
以上、だいぶすっきりした処理ができたと思います。
この一連の計算をデータフレームでやろうとすると、どうなるでしょうか?
少し見てみましょう。
grade1 <- read.table("grade1.csv" , header=T , sep=",")
grade2 <- read.table("grade2.csv" , header=T , sep=",")
grade3 <- read.table("grade3.csv" , header=T , sep=",")
grade4 <- read.table("grade4.csv" , header=T , sep=",")
grade5 <- read.table("grade5.csv" , header=T , sep=",")
grade6 <- read.table("grade6.csv" , header=T , sep=",")
grade1$grade <- rep(1 , 3) ; grade2$grade <- rep(2 , 3) #学年を入力
grade3$grade <- rep(3 , 3) ; grade4$grade <- rep(4 , 3)
grade5$grade <- rep(5 , 3) ; grade6$grade <- rep(6 , 4)
df <- rbind(grade1 , grade2 , grade3 , grade4 , grade5 , grade6)
df <- df[,c(7,1:6)]
df
grade meibo jp math eng soc sci
1 1 1 56 55 63 65 60
2 1 2 74 67 78 80 73
3 1 3 88 87 90 92 87
4 2 1 70 61 72 72 70
5 2 2 72 68 77 77 73
6 2 3 81 75 88 93 86
7 3 1 69 61 70 73 68
8 3 2 56 47 63 66 61
9 3 3 88 87 88 93 85
10 4 1 71 68 72 75 67
11 4 2 68 62 73 77 70
12 4 3 74 65 82 83 82
13 5 1 75 66 82 83 80
14 5 2 74 71 78 79 77
15 5 3 64 62 73 78 70
16 6 1 88 87 88 93 85
17 6 2 77 74 80 81 78
18 6 3 69 67 71 72 70
19 6 4 79 74 80 84 77データフレーム作成までのスクリプトです。
データフレームにする場合はcsvに学年が入っていないので、学年の列を作成する必要があります。
df$sum <- apply(df[,3:7] , 1 , sum)
df
grade meibo jp math eng soc sci sum
1 1 1 56 55 63 65 60 299
2 1 2 74 67 78 80 73 372
3 1 3 88 87 90 92 87 444
4 2 1 70 61 72 72 70 345
5 2 2 72 68 77 77 73 367 #・・・省略データフレームさえ作ってしまえば、あとは行ごとに計算するだけです。
apply()を使えば簡単に求めることができますが、1年生の成績のみを抽出したりする際は、subset()が必須です。
2階層リストの実用例

次は少し学校の規模を大きくしてみましょう。学年の下にクラスがある場合を考えていきます。
問題設定はこちらです。
「学年ごとに複数のクラスがある学校があります。1~5年生は2クラス、6年生だけ3クラスあり、1クラス3人か4人入っています。 この状況をリスト化し、各学生の成績をまとめたい。csvには合計点がないので、リスト化した後にこれを計算したい」
gd1class1 <- read.table("gd1class1.csv" , header=T , sep=",")
gd1class2 <- read.table("gd1class2.csv" , header=T , sep=",")
gd2class1 <- read.table("gd2class1.csv" , header=T , sep=",")
gd2class2 <- read.table("gd2class2.csv" , header=T , sep=",")
gd3class1 <- read.table("gd3class1.csv" , header=T , sep=",")
gd3class2 <- read.table("gd3class2.csv" , header=T , sep=",")
gd4class1 <- read.table("gd4class1.csv" , header=T , sep=",")
gd4class2 <- read.table("gd4class2.csv" , header=T , sep=",")
gd5class1 <- read.table("gd5class1.csv" , header=T , sep=",")
gd5class2 <- read.table("gd5class2.csv" , header=T , sep=",")
gd6class1 <- read.table("gd6class1.csv" , header=T , sep=",")
gd6class2 <- read.table("gd6class2.csv" , header=T , sep=",")
gd6class3 <- read.table("gd6class3.csv" , header=T , sep=",")
list <- list()
list <- c(list , list( list(gd1class1 , gd1class2) )
, list( list(gd2class1 , gd2class2) )
, list( list(gd3class1 , gd3class2) )
, list( list(gd4class1 , gd4class2) )
, list( list(gd5class1 , gd5class2) )
, list( list(gd6class1 , gd6class2 , gd6class3) ) )
扱うcsvも増えたためスクリプトは長くなりましたが、やっていることは1階層リストの例と同じです。
まずは順序通り、リスト化してみます。
> list
[[1]]
[[1]][[1]]
meibo jp math eng soc sci
1 1 56 55 63 65 60
2 2 74 67 78 80 73
3 3 88 87 90 92 87
[[1]][[2]]
meibo jp math eng soc sci
1 1 81 75 88 93 86
2 2 65 57 68 71 67
3 3 78 75 78 80 74
[[2]]
[[2]][[1]]
meibo jp math eng soc sci
1 1 70 61 72 72 70
2 2 72 68 77 77 73
3 3 81 75 88 93 86
[[2]][[2]]
meibo jp math eng soc sci
1 1 78 75 78 80 74
2 2 45 36 50 50 49
3 3 88 87 90 91 85
[[3]]
[[3]][[1]]
meibo jp math eng soc sci
1 1 69 61 70 73 68
2 2 56 47 63 66 61
3 3 88 87 88 93 85
[[3]][[2]]
meibo jp math eng soc sci
1 1 77 74 80 81 78
2 2 69 67 71 72 70
3 3 79 74 80 84 77
[[4]]
[[4]][[1]]
meibo jp math eng soc sci
1 1 71 68 72 75 67
2 2 68 62 73 77 70
3 3 74 65 82 83 82
[[4]][[2]]
meibo jp math eng soc sci
1 1 88 87 90 92 87
2 2 60 59 69 71 66
3 3 75 66 82 83 80
4 4 99 82 78 88 79
# ・・・省略…なるほど!
階層が増えるとデータの把握が大変なんじゃないかと思いましたが、2階層程度であればなんとなくわかるものですね!
1年生の枠の中に、1クラスと2クラスの生徒がいる。容易にわかりますね!
fun1 <- function(x){ x$sum <- apply(x[,2:6] , 1 , sum) ; return(x) } #短縮系
fun2 <- function(x){ y <- lapply(x , fun1) ; return(y) } #短縮系
list <- lapply(list , fun2)
しかし計算の方は意味不明
階層が増えると、作成したfun1のみでは対処できないことが分かったので、新しくfun2というものを定義しました。
簡単に言うとlapply()を2つ重ねた計算になるのですが、この操作についての説明はこの記事のテーマから外れているので、別の記事にてお話ししたいと思います。
…applyファミリーと言わず、lapply()単独の記事が必要ですね(苦笑)
2017/10/20 追記:おまたせしました!
参考記事:階層リストはこう操作する!R言語のlapply,sapplyのイメージを学ぼう
list
[[1]]
[[1]][[1]]
meibo jp math eng soc sci sum
1 1 56 55 63 65 60 299
2 2 74 67 78 80 73 372
3 3 88 87 90 92 87 444
[[1]][[2]]
meibo jp math eng soc sci sum
1 1 81 75 88 93 86 423
2 2 65 57 68 71 67 328
3 3 78 75 78 80 74 385
[[2]]
[[2]][[1]]
meibo jp math eng soc sci sum
1 1 70 61 72 72 70 345
2 2 72 68 77 77 73 367
3 3 81 75 88 93 86 423
[[2]][[2]]
meibo jp math eng soc sci sum
1 1 78 75 78 80 74 385
2 2 45 36 50 50 49 230
3 3 88 87 90 91 85 441
# ・・・省略計算結果はこちらになります。
階層が2つあっても、きちんと計算ができていることが分かります。
この問題においてデータフレームを活用しようとすると、実は面倒です。
csvが生徒の名簿と成績しか載っていない貧弱なデータなので、学年とクラスの列をR上で付加しないといけないからです。
gd1class1 <- read.table("gd1class1.csv" , header=T , sep=",")
gd1class2 <- read.table("gd1class2.csv" , header=T , sep=",")
gd2class1 <- read.table("gd2class1.csv" , header=T , sep=",")
gd2class2 <- read.table("gd2class2.csv" , header=T , sep=",")
gd3class1 <- read.table("gd3class1.csv" , header=T , sep=",")
gd3class2 <- read.table("gd3class2.csv" , header=T , sep=",")
gd4class1 <- read.table("gd4class1.csv" , header=T , sep=",")
gd4class2 <- read.table("gd4class2.csv" , header=T , sep=",")
gd5class1 <- read.table("gd5class1.csv" , header=T , sep=",")
gd5class2 <- read.table("gd5class2.csv" , header=T , sep=",")
gd6class1 <- read.table("gd6class1.csv" , header=T , sep=",")
gd6class2 <- read.table("gd6class2.csv" , header=T , sep=",")
gd6class3 <- read.table("gd6class3.csv" , header=T , sep=",")
gd1class1$grade <- rep(1 , nrow(gd1class1)) #csvにない学年を挿入
# 省略・・・(13行)
gd1class1$class <- rep(1 , nrow(gd1class1)) #csvにないクラスを挿入
# 省略・・・(13行)
df <- rbind(gd1class1 , gd1class2 , gd2class1 , gd2class2 , gd3class1 ,
gd3class2 , gd4class1 , gd4class2 , gd5class1 , gd5class2 ,
gd6class1 , gd6class2 , gd6class3)
df <- df[,c(7,8,1:6)]
上記のスクリプトでは省略していますが、csvにない学年とクラスの列を挿入するだけで、かなりの行数になります(省略したのは26行)。
この場合はリストに軍配が上がることでしょう。
最後に(まとめ)
ここまでで、3つの例を用いてListの有用性を考えてみました。
以下はまとめになります。
Listが使える場面
3つの例で学ぶべきリストの有用性は以下の通りです。
- 長さが違うベクトルを、1つにまとめることができる
- 階層別にデータを入れることで、データの判別・集計・分析が容易になる
長さの違うものをまとめられるという、データフレームにはない特徴を上手く活用できるようになると、Rの活用の幅が広がります。多くのベクトルをまとめられるという点で、蓬莱さんも今後研究で使っていこうかなと思っています。
学校を例にして説明した階層別リストは、lapply()の難しさもあって慣れが必要かもしれません。こちらは時間のある時に、じっくりと学んでみてください。
リスト初心者の妄言もあると思いますが、この記事を読んでリストも使えそうだなと思っていただければ幸いです。
データフレームと使い分けよう
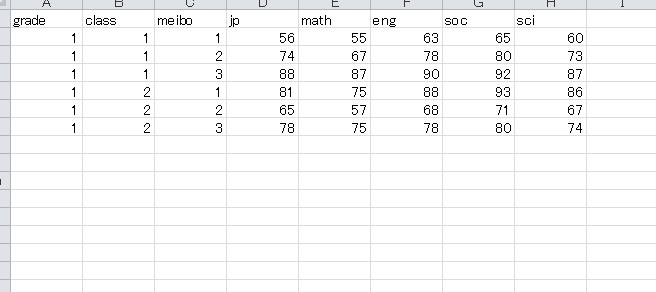
逆にリストが使いにくい・使えない場面があります。
それはcsvがきちんと成形されている場合です。
画像を見ると、csvの段階ですでに学年やクラスが割り振られていますよね。この状態は、言うなればすでにデータフレームが完成されている状態です。
完成されたデータフレームからリストに分割するなんて、はっきり言って意味のない行為ですよね。この場合は、大人しくデータフレームでの処理をしていくべきです。
…もしかしたら、自分がリストと縁がなかったのって、csvを提供してくれる人がきちんと整理した状態で渡してくれたからなのでしょうか。
だとしたら、盛大なる感謝をしないといけませんね(笑)